Journals > > Topics > Digital Image Processing
Digital Image Processing|33 Article(s)
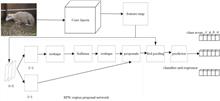
Few-Shot Object Detection Based on Association and Discrimination
Jianli Jia, Huiyan Han, Liqun Kuang, Fangzheng Han, Xinyi Zheng, and Xiuquan Zhang
Deep learning-based object detection algorithms have matured considerably. However, detecting novel classes based on a limited number of samples remains challenging as deep learning can easily lead to feature space degradation under few-shot conditions. Most of the existing methods employ a holistic fine-tuning paradigm to pretrain on base classes with abundant samples and subsequently construct feature spaces for the novel classes. However, the novel class implicitly constructs a feature space based on multiple base classes, and its structure is relatively dispersed, thereby leading to poor separability between the base class and the novel class. This study proposes the method of associating a novel class with a similar base class and then discriminating each class for few-shot object detection. By introducing dynamic region of interest headers, the model improves the utilization of training samples and explicitly constructs a feature space for new classes based on the semantic similarity between the two. Furthermore, by decoupling the classification branches of the base and new classes, integrating channel attention modules, and implementing boundary loss functions, we substantially improve the separability between the classes. Experimental results on the standard PASCAL VOC dataset reveal that our method surpasses the nAP50 mean scores of TFA, MPSR, and DiGeo by 10.2, 5.4, and 7.8, respectively. Deep learning-based object detection algorithms have matured considerably. However, detecting novel classes based on a limited number of samples remains challenging as deep learning can easily lead to feature space degradation under few-shot conditions. Most of the existing methods employ a holistic fine-tuning paradigm to pretrain on base classes with abundant samples and subsequently construct feature spaces for the novel classes. However, the novel class implicitly constructs a feature space based on multiple base classes, and its structure is relatively dispersed, thereby leading to poor separability between the base class and the novel class. This study proposes the method of associating a novel class with a similar base class and then discriminating each class for few-shot object detection. By introducing dynamic region of interest headers, the model improves the utilization of training samples and explicitly constructs a feature space for new classes based on the semantic similarity between the two. Furthermore, by decoupling the classification branches of the base and new classes, integrating channel attention modules, and implementing boundary loss functions, we substantially improve the separability between the classes. Experimental results on the standard PASCAL VOC dataset reveal that our method surpasses the nAP50 mean scores of TFA, MPSR, and DiGeo by 10.2, 5.4, and 7.8, respectively.
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2024
- Vol. 61, Issue 8, 0837015 (2024)

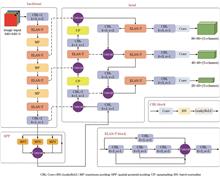
Real-Time Pedestrian Detection Based on Dual-Modal Relevant Image Fusion
Chengcheng Bi, Miaohua Huang, Ruoying Liu, and Liangzi Wang
In order to solve the problems of high missing detection rate of single-model images and low detection speed of existing dual-model image fusion in pedestrian detection tasks under low visibility scenes, a lightweight pedestrian detection network based on dual-model relevant image fusion is proposed. The network model is designed based on YOLOv7-Tiny, and the backbone network is embedded with RAMFusion, which is used to extract and aggregate dual-model image complementary features. The 1×1 convolution of feature extraction is replaced by coordinate convolution with spatial awareness. Soft-NMS is introduced to improve the pedestrian omission in the cluster. The attention mechanism module is embedded to improve the accuracy of model detection. The ablation experiments in public infrared and visible pedestrian dataset LLVIP show that compared with other fusion methods, the missing detection rate of pedestrians is reduced and the detection speed of the proposed method is significantly increased. Compared with YOLOv7-Tiny, the detection accuracy of the improved model is increased by 2.4%, and the detection frames per second is up to 124 frame/s, which can meet the requirements of real-time pedestrian detection in low-visibility scenes. In order to solve the problems of high missing detection rate of single-model images and low detection speed of existing dual-model image fusion in pedestrian detection tasks under low visibility scenes, a lightweight pedestrian detection network based on dual-model relevant image fusion is proposed. The network model is designed based on YOLOv7-Tiny, and the backbone network is embedded with RAMFusion, which is used to extract and aggregate dual-model image complementary features. The 1×1 convolution of feature extraction is replaced by coordinate convolution with spatial awareness. Soft-NMS is introduced to improve the pedestrian omission in the cluster. The attention mechanism module is embedded to improve the accuracy of model detection. The ablation experiments in public infrared and visible pedestrian dataset LLVIP show that compared with other fusion methods, the missing detection rate of pedestrians is reduced and the detection speed of the proposed method is significantly increased. Compared with YOLOv7-Tiny, the detection accuracy of the improved model is increased by 2.4%, and the detection frames per second is up to 124 frame/s, which can meet the requirements of real-time pedestrian detection in low-visibility scenes.
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2024
- Vol. 61, Issue 8, 0837014 (2024)

Regular Building Outline Extraction Based on Multi-Level Minimum Bounding Rectangle
Gang Li, Ke Liu, Hongchao Ma, Liang Zhang, and Jialin Yuan
Building outlines serve as data sources for various applications. However, accurately extracting outlines from scattered and irregular point clouds presents a challenge. To address this issue, a method utilizing the concept of the multi-level minimum bounding rectangle (MBR) is proposed for extracting precise outlines of regular buildings. Initially, the boundary points are segmented into groups using an iterative region growing technique. Subsequently, the group with the maximum boundary points is utilized to identify the initial MBR. The initial MBR is then decomposed into multi-level rectangles, ensuring that the boundary points align with rectangles of different levels. Ultimately, the outlines are generated using the multi-level MBR approach. To evaluate the effectiveness of the proposed method, experiments were conducted on regular buildings in Vaihingen. The results demonstrate that the proposed method achieves an accurate initial MBR with a slightly enhanced efficiency compared to the minimum area and the maximum overlapping methods. The root mean square errors of the extracted outline corners measure 0.71 m, surpassing the performance of four other comparison methods. In conclusion, the proposed method enables the effective extraction of outlines from regular buildings, providing a valuable contribution to subsequent three-dimensional reconstruction tasks. Building outlines serve as data sources for various applications. However, accurately extracting outlines from scattered and irregular point clouds presents a challenge. To address this issue, a method utilizing the concept of the multi-level minimum bounding rectangle (MBR) is proposed for extracting precise outlines of regular buildings. Initially, the boundary points are segmented into groups using an iterative region growing technique. Subsequently, the group with the maximum boundary points is utilized to identify the initial MBR. The initial MBR is then decomposed into multi-level rectangles, ensuring that the boundary points align with rectangles of different levels. Ultimately, the outlines are generated using the multi-level MBR approach. To evaluate the effectiveness of the proposed method, experiments were conducted on regular buildings in Vaihingen. The results demonstrate that the proposed method achieves an accurate initial MBR with a slightly enhanced efficiency compared to the minimum area and the maximum overlapping methods. The root mean square errors of the extracted outline corners measure 0.71 m, surpassing the performance of four other comparison methods. In conclusion, the proposed method enables the effective extraction of outlines from regular buildings, providing a valuable contribution to subsequent three-dimensional reconstruction tasks.
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2024
- Vol. 61, Issue 8, 0837013 (2024)
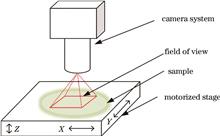
Microscopic Image Stitching Algorithm Based on Stage Motion Information
Jiaguang Huang, Zhenming Yu, Guojin Peng, Hui Gan, and Lü Meini
Traditional non-real-time image stitching methods can easily lead to global stitching interruption due to local image misalignment. In addition, microscopic images have numerous similar microstructures, causing problems such as long feature detection time and high misalignment rate. To address these issues, a microscopic image prediction stitching algorithm based on carrier stage motion information is proposed. First, the size of the overlapping area between adjacent images is determined by controlling the XY axis movement distance of the electric carrier stage. The accelerated robust feature algorithm is then used to detect feature points in the overlapping area of the image. Second, the range of feature points to be matched is predicted based on the position relationship of the images, and the feature point with the minimum Euclidean distance is selected within the predicted range for matching. Finally, matching point pairs are coarsely screened by the slope of the matching feature points, and precise matching is performed using the random sample consensus algorithm to calculate the homography matrix and complete the image stitching. The improved weighted average algorithm is used to fuse the stitched images. Experimental results show that the proposed algorithm achieves a superior matching rate improvement of 7.95% to 26.52% compared to those obtained via the brute force and fast library for approximate nearest neighbors algorithms, effectively improving the registration accuracy. Moreover, at a resolution of 1600×1200, the multi-image stitching rate of 2 frame·s-1 achieves better results than those obtained by the AutoStitch software. Traditional non-real-time image stitching methods can easily lead to global stitching interruption due to local image misalignment. In addition, microscopic images have numerous similar microstructures, causing problems such as long feature detection time and high misalignment rate. To address these issues, a microscopic image prediction stitching algorithm based on carrier stage motion information is proposed. First, the size of the overlapping area between adjacent images is determined by controlling the XY axis movement distance of the electric carrier stage. The accelerated robust feature algorithm is then used to detect feature points in the overlapping area of the image. Second, the range of feature points to be matched is predicted based on the position relationship of the images, and the feature point with the minimum Euclidean distance is selected within the predicted range for matching. Finally, matching point pairs are coarsely screened by the slope of the matching feature points, and precise matching is performed using the random sample consensus algorithm to calculate the homography matrix and complete the image stitching. The improved weighted average algorithm is used to fuse the stitched images. Experimental results show that the proposed algorithm achieves a superior matching rate improvement of 7.95% to 26.52% compared to those obtained via the brute force and fast library for approximate nearest neighbors algorithms, effectively improving the registration accuracy. Moreover, at a resolution of 1600×1200, the multi-image stitching rate of 2 frame·s-1 achieves better results than those obtained by the AutoStitch software.
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2024
- Vol. 61, Issue 8, 0837012 (2024)
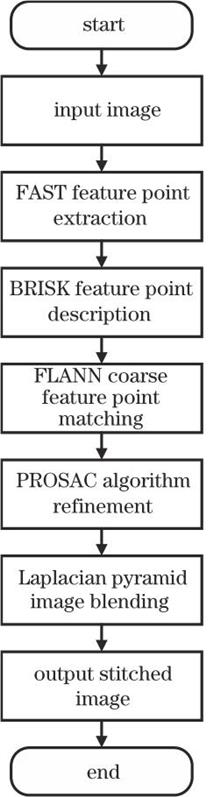
Fast Image-Stitching Algorithm of Dangerous Objects Under Vehicles
Jianjun Zhang, and Xin Jin
To address challenges involving low accuracy in feature point matching, low matching speed, cracks at the stitching points, and extended stitching time in vehicle undercarriage threat detection imaging, an optimized image-stitching algorithm is proposed. First, the corner detection (FAST) algorithm is used to extract image feature points, and then, the binary robust invariant scalable key point (BRISK) algorithm is used to describe the retained feature points. Second, the fast nearest neighbor search (FLANN) algorithm is used for coarse matching. Next, the progressive uniform sampling (PROSAC) algorithm is used for feature point purification. Finally, the Laplace pyramid algorithm is used for image fusion and stitching. The experimental results show that, when compared with SIFT, SURF, and ORB algorithms, the proposed algorithm improves the image feature matching accuracy by 13.10 percentage points, 8.59 percentage points, and 11.27 percentage points, respectively, in the image data of dangerous objects under the vehicle. The matching time is shortened by 76.26%, 85.36%, and 10.27%, respectively. The image-stitching time is shortened by 63.73%, 64.21%, and 20.07%, respectively, and there are no evident cracks at the stitching point. Therefore, the image-stitching algorithm based on the combination of FAST, BRISK, PROSAC, and Laplace pyramid is a high-quality fast image-stitching algorithm. To address challenges involving low accuracy in feature point matching, low matching speed, cracks at the stitching points, and extended stitching time in vehicle undercarriage threat detection imaging, an optimized image-stitching algorithm is proposed. First, the corner detection (FAST) algorithm is used to extract image feature points, and then, the binary robust invariant scalable key point (BRISK) algorithm is used to describe the retained feature points. Second, the fast nearest neighbor search (FLANN) algorithm is used for coarse matching. Next, the progressive uniform sampling (PROSAC) algorithm is used for feature point purification. Finally, the Laplace pyramid algorithm is used for image fusion and stitching. The experimental results show that, when compared with SIFT, SURF, and ORB algorithms, the proposed algorithm improves the image feature matching accuracy by 13.10 percentage points, 8.59 percentage points, and 11.27 percentage points, respectively, in the image data of dangerous objects under the vehicle. The matching time is shortened by 76.26%, 85.36%, and 10.27%, respectively. The image-stitching time is shortened by 63.73%, 64.21%, and 20.07%, respectively, and there are no evident cracks at the stitching point. Therefore, the image-stitching algorithm based on the combination of FAST, BRISK, PROSAC, and Laplace pyramid is a high-quality fast image-stitching algorithm.
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2024
- Vol. 61, Issue 8, 0837011 (2024)

Infrared and Visible Image Fusion Based on Gradient Domain-Guided Filtering and Significance Analysis
Tingbo Si, Fangxiu Jia, Lü Ziqiang, and Zikang Wang
Traditional multi-scale fusion methods cannot highlight target information and often miss details and textures in fusion images. Therefore, an infrared and visible light image fusion method based on gradient domain-guided filtering and saliency detection is proposed. This method utilizes gradient domain-guided filtering to decompose the input image into basic and detail layers and uses a weighted global contrast method to decompose the basic layer into feature and difference layers. In the fusion process, phase consistency combined with weighted local energy, local entropy combined with weighted least squares optimization, and average rules are used to fuse feature layers, difference layers, and detail layers. The experimental results show that the multiple indicators of the proposed fusion method are significantly improved compared to those of other methods, resulting in a superior visual effect of the image. The proposed method is highly effective in highlighting target information, preserving contour details, and improving contrast and clarity. Traditional multi-scale fusion methods cannot highlight target information and often miss details and textures in fusion images. Therefore, an infrared and visible light image fusion method based on gradient domain-guided filtering and saliency detection is proposed. This method utilizes gradient domain-guided filtering to decompose the input image into basic and detail layers and uses a weighted global contrast method to decompose the basic layer into feature and difference layers. In the fusion process, phase consistency combined with weighted local energy, local entropy combined with weighted least squares optimization, and average rules are used to fuse feature layers, difference layers, and detail layers. The experimental results show that the multiple indicators of the proposed fusion method are significantly improved compared to those of other methods, resulting in a superior visual effect of the image. The proposed method is highly effective in highlighting target information, preserving contour details, and improving contrast and clarity.
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2024
- Vol. 61, Issue 8, 0837010 (2024)
Augmented Edge Graph Convolutional Networks for Semantic Segmentation of 3D Point Clouds
Lujian Zhang, Yuanwei Bi, Yaowen Liu, and Yansen Huang
Currently, most point cloud semantic segmentation methods based on graph convolution overlook the critical aspect of edge construction, resulting in an incomplete representation of the features of local regions. To address this limitation, we propose a novel graph convolutional network AE-GCN that integrates edge enhancement with an attention mechanism. First, we incorporate neighboring point features into the edges rather than solely considering feature differences between the central point and its neighboring points. Second, introducing an attention mechanism ensures a more comprehensive utilization of local information within the point cloud. Finally, we employ a U-Shape segmentation structure to improve the network's semantic point cloud segmentation adaptability. Our experiments on two public datasets, Toronto_3D and S3DIS, demonstrate that AE-GCN outperforms most current methods. Specifically, on the Toronto_3D dataset, AE-GCN achieves a competitive average intersection-to-union ratio of 80.3% and an overall accuracy of 97.1%. Furthermore, on the S3DIS dataset, the model attains an average intersection-to-union ratio of 68.0% and an overall accuracy of 87.2%. Currently, most point cloud semantic segmentation methods based on graph convolution overlook the critical aspect of edge construction, resulting in an incomplete representation of the features of local regions. To address this limitation, we propose a novel graph convolutional network AE-GCN that integrates edge enhancement with an attention mechanism. First, we incorporate neighboring point features into the edges rather than solely considering feature differences between the central point and its neighboring points. Second, introducing an attention mechanism ensures a more comprehensive utilization of local information within the point cloud. Finally, we employ a U-Shape segmentation structure to improve the network's semantic point cloud segmentation adaptability. Our experiments on two public datasets, Toronto_3D and S3DIS, demonstrate that AE-GCN outperforms most current methods. Specifically, on the Toronto_3D dataset, AE-GCN achieves a competitive average intersection-to-union ratio of 80.3% and an overall accuracy of 97.1%. Furthermore, on the S3DIS dataset, the model attains an average intersection-to-union ratio of 68.0% and an overall accuracy of 87.2%.
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2024
- Vol. 61, Issue 8, 0837009 (2024)
Projection Domain Denoising Method for Multi-Energy Computed Tomography via Dual-Stream Transformer
Shunxin Ouyang, Zaifeng Shi, Fanning Kong, Lili Zhang, and Qingjie Cao
The multi-energy computed tomography (CT) technique can resolve the absorption rates of various energy X-ray photons in human tissues, representing a significant advancement in medical imaging. By addressing the challenge of swift degradation in reconstructed image quality, primarily due to non-ideal effects such as quantum noise, a dual-stream Transformer network structure is introduced. This structure utilises the shifted-window multi-head self-attention denoising approach for projection data. The shifted windows Transformer extracts the global features of the projection data, while the locally-enhanced window Transformer focuses on local features. This dual approach capitalizes on the non-local self-similarity of the projection data to maintain its inherent structure, subsequently merged by residual convolution. For model training oversight, a hybrid loss function incorporating non-local total variation is employed, which enhances the network model's sensitivity to the inner details of the projected data. Experimental results demonstrate that our method's processed projection data achieve a peak signal to noise ratio (PSNR) of 37.7301 dB, structure similarity index measurement (SSIM) of 0.9944, and feature similarity index measurement (FSIM) of 0.9961. Relative to leading denoising techniques, the proposed method excels in noise reduction while preserving more inner features, crucial for subsequent accurate diagnostics. The multi-energy computed tomography (CT) technique can resolve the absorption rates of various energy X-ray photons in human tissues, representing a significant advancement in medical imaging. By addressing the challenge of swift degradation in reconstructed image quality, primarily due to non-ideal effects such as quantum noise, a dual-stream Transformer network structure is introduced. This structure utilises the shifted-window multi-head self-attention denoising approach for projection data. The shifted windows Transformer extracts the global features of the projection data, while the locally-enhanced window Transformer focuses on local features. This dual approach capitalizes on the non-local self-similarity of the projection data to maintain its inherent structure, subsequently merged by residual convolution. For model training oversight, a hybrid loss function incorporating non-local total variation is employed, which enhances the network model's sensitivity to the inner details of the projected data. Experimental results demonstrate that our method's processed projection data achieve a peak signal to noise ratio (PSNR) of 37.7301 dB, structure similarity index measurement (SSIM) of 0.9944, and feature similarity index measurement (FSIM) of 0.9961. Relative to leading denoising techniques, the proposed method excels in noise reduction while preserving more inner features, crucial for subsequent accurate diagnostics.
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2024
- Vol. 61, Issue 8, 0837008 (2024)
Depth Image Super-Resolution Reconstruction Network Based on Dual Feature Fusion Guidance
Haowen Geng, Yu Wang, and Yanling Xin
A depth image super-resolution reconstruction network (DF-Net) based on dual feature fusion guidance is proposed to address the issues of texture transfer and depth loss in color image guided deep image super-resolution reconstruction algorithms. To fully utilize the correlation between depth and intensity features, a dual channel fusion module (DCM) and a dual feature guided reconstruction module (DGM) are used to perform deep recovery and reconstruction in the network model. The multi-scale features of depth and intensity information are extracted using a input pyramid structure: DCM performs feature fusion and enhancement between channels based on a channel attention mechanism for depth and intensity features; DGM provides dual feature guidance for reconstruction by adaptively selecting and fusing depth and intensity features, increasing the guidance effect of depth features, and overcoming the issues of texture transfer and depth loss. The experimental results show that the peak signal-to-noise ratio (PSNR) and root mean square error (RMSE) of the proposed method are superior to those of methods such as RMRF, JBU, and Depth Net. Compared to the other methods, the PSNR value of the 4× super-resolution reconstruction results increased by an average of 6.79 dB, and the RMSE decreased by an average of 0.94, thus achieving good depth image super-resolution reconstruction results. A depth image super-resolution reconstruction network (DF-Net) based on dual feature fusion guidance is proposed to address the issues of texture transfer and depth loss in color image guided deep image super-resolution reconstruction algorithms. To fully utilize the correlation between depth and intensity features, a dual channel fusion module (DCM) and a dual feature guided reconstruction module (DGM) are used to perform deep recovery and reconstruction in the network model. The multi-scale features of depth and intensity information are extracted using a input pyramid structure: DCM performs feature fusion and enhancement between channels based on a channel attention mechanism for depth and intensity features; DGM provides dual feature guidance for reconstruction by adaptively selecting and fusing depth and intensity features, increasing the guidance effect of depth features, and overcoming the issues of texture transfer and depth loss. The experimental results show that the peak signal-to-noise ratio (PSNR) and root mean square error (RMSE) of the proposed method are superior to those of methods such as RMRF, JBU, and Depth Net. Compared to the other methods, the PSNR value of the 4× super-resolution reconstruction results increased by an average of 6.79 dB, and the RMSE decreased by an average of 0.94, thus achieving good depth image super-resolution reconstruction results.
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2024
- Vol. 61, Issue 8, 0837007 (2024)
Template Update Mechanism for Single Target Tracking Incorporating Memory Information
Yuwen Mao, Baozhen Ge, Jianing Quan, and Qibo Chen
Single target tracking algorithm based on Siamese architecture suffers from untimely target state update. To address this issue, a generic template update mechanism is proposed based on the dynamic fusion of templates and memory information. The mechanism uses a dual module fusion update strategy. The short-term memory information of search feature map is fused using a memory fusion module to capture target variations. The trusted tracking result of the previous frame is used as a dynamic template. The original and dynamic templates are fused using a weight fusion module from the correlated feature perspective to achieve more accurate target localization using the original and short-term memories during the tracking process. The template update mechanism is applied to three mainstream algorithms, SiamRPN, SiamRPN++ and RBO, and experiments are conducted on the VOT2019 public dataset. The results show that the performance of the algorithms is effectively improved after applying the mechanism. Specially, for the SiamRPN++ algorithm, the average overlap expectation is improved by 6.67%, the accuracy is improved by 0.17%, and the robustness is enhanced by 5.39% after applying the template update mechanism. In addition, the SiamRPN++ algorithm with the mechanism has better tracking performance in complex scenarios with occlusion, deformation and background interference. Single target tracking algorithm based on Siamese architecture suffers from untimely target state update. To address this issue, a generic template update mechanism is proposed based on the dynamic fusion of templates and memory information. The mechanism uses a dual module fusion update strategy. The short-term memory information of search feature map is fused using a memory fusion module to capture target variations. The trusted tracking result of the previous frame is used as a dynamic template. The original and dynamic templates are fused using a weight fusion module from the correlated feature perspective to achieve more accurate target localization using the original and short-term memories during the tracking process. The template update mechanism is applied to three mainstream algorithms, SiamRPN, SiamRPN++ and RBO, and experiments are conducted on the VOT2019 public dataset. The results show that the performance of the algorithms is effectively improved after applying the mechanism. Specially, for the SiamRPN++ algorithm, the average overlap expectation is improved by 6.67%, the accuracy is improved by 0.17%, and the robustness is enhanced by 5.39% after applying the template update mechanism. In addition, the SiamRPN++ algorithm with the mechanism has better tracking performance in complex scenarios with occlusion, deformation and background interference.
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2024
- Vol. 61, Issue 8, 0837006 (2024)
Topics
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20